The previous section helped us understand two major syscalls namely brk and sbrk. I also implemented a basic malloc technique using these syscalls and addressed the problem on direct accessing these syscalls, i.e. The order of Free should be exact reverse of malloc, else would lead to segmentation violation.
Another problem worth mentioning is, system calls are expensive due to context switch between kernel space and user space; Moreover this might also lead to unnecessary suspension of process.
Approach to solution. To address the mentioned problems we should reduce the number of time syscall’s is made and secondly rather than reverting or contracting the data segment we should create a hole in the heap which could be reused.
Solution. To make the above challenges addressable we need to use a notion called memory pooling, i.e. pre-fetch a big chunk of memory and cut a piece from it when required. This cut piece is given back to the chunk on free function( not given back to the Kernel, but rather pooled).
Challenge. The mentioned solution is not straight forward; first allocation should not provide you with memory very big compared to the requested size( causing Internal Fragmentation) and the time taken to process the request should be reasonable. Second the freeing of memory should happen in constant time, i.e.O(1).
Simplest solution that addresses the mentioned challenges is SLOB, i.e. Simple List Of Blocks. As name suggests its a list holding reference to “set of chunks” of same size.The list is arranged in ascending order based on size of the chunk it holds.To make this approach work, the memory needed for the process is approximately precomputed , prefetched and made into SLOB before main function is called.
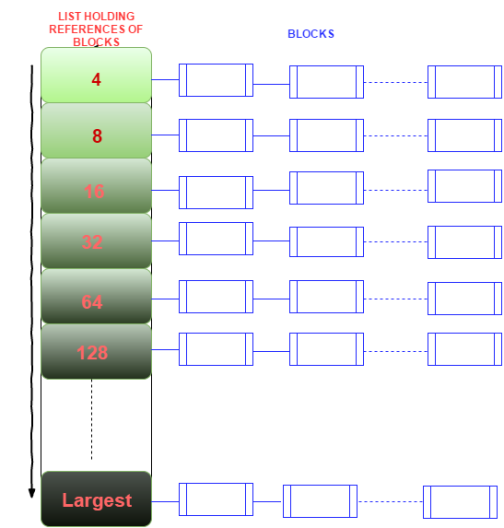
The Above figure is a simple representation of SLOB.
On Malloc the list is searched for the first fit( which in SLOB is also the best fit because of its ascending property). If the desired requested size can be allocated, then the chunk is removed from the list and its starting address is returned, else NULL is returned. The complexity of the fetch is O(N), where N is the length of the list, i.e. linear complexity.
Free just takes the starting address of the chunk and provides no other information about the size or other information about the cache( or element) to which the chunk belongs; but on free the released chunk needs to identify the desired cache to which the chunk belongs.With just starting address as parameter,it is not possible to return the chunk to the desired cache in constant time, unless the chunk holds some reference of the ownership. To make this work a notion called boundary tag is used.
Boundary tag: Either before or after each chunk a record is added, holding the reference of the element to which the chunk belongs. This boundary tag is provided to each chunk. The total size of each chunk is chunk-size + boundary tag. The size of the boundary tag is of great importance; Bigger it becomes , overhead of book keeping data becomes proportionately larger, but at the same time the size should be efficient enough to hold required data so that chunk can be returned to the respective element it belongs. Study suggests that boundary tag should not be greater than 10% of the total payload memory. To implement SLOB the size of the tag would be a word length, i.e. 32bits in case of 32bit system to hold the reference of the owned element.

The diagram on the left is an abridged representation of the boundary tag.
Abstraction.When malloced the address at the end of the tag is returned; therefore, the user is abstracted from underneath implementation of the allocation.
In many scientific publications the boundary tagging is called hidden header field.
when free is called it gets end address of the boundary tag, i.e. the starting address of the chunk. To this address when the size of the boundary tag is negated we would get the reference of the chunk’s tag. This provides us with the required information about the element to which the chunk should be returned. The complexity of the Free is O(1).
Usage:
This notion of SLOB is used in many RTOS that works on flat memory model. among many, One worth mentioning is OSE166’s redarrow platform. This platform was majorly used on many primitive mobile devices.
Another place with prominent usage is SLAB implementation in Linux kernel; Where the kernel data structures are alloced using such an implementation, but with a slight twist; which we will discuss in much detail as we progress.
Many Middlewares uses this approach to build a wrapper around the standard library to make access to memory faster.
Conclusion.This article provided us the semantic understanding of SLOB, In the next article we would discuss a method to implement the SLOB and would also discuss the pros and cons of this algorithm.
Definitions used in this articles:
Internal fragmentation: is the wasted space within each allocated block because of rounding up from the actual requested allocation to the allocation granularity.
Flat memory model or linear memory model refers to a memory addressing paradigm in which “memory appears to the program as a single contiguous address space.”The CPU can directly (and linearly) address all of the available memory locations without having to resort to any sort of memory segmentation or paging schemes.
References and further study:
- https://en.wikipedia.org/wiki/Big_O_notation#Big_Omega_notation
- https://en.wikipedia.org/wiki/Fragmentation_(computing)
- https://en.wikipedia.org/wiki/SLOB
- https://en.wikipedia.org/wiki/Flat_memory_model



