This series of articles tries a hand on hand analysis of memory management policies accommodated in acclaimed Unix-like operating systems like OpenSolaris, FreeBSD with Linux.
Memory management conventionally has three major policies.
- Fetch Policy: When to fetch a page from auxiliary memory.
- Placement Policy: Where to place the fetched page in main memory.
- Replacement Policy: Which page to replace in case of memory shortage.
The mentioned policies are well studied and reasoned( Though I will write on this as well), nevertheless another policy which directly impacts the performance of a system is scan rate policy.
Rest of this specific work will focus on this policy and its approach in different operating system.
What is a scan rate policy?
Operating systems keeps updating the position of the allocated pages in their corresponding list based on its access frequency and other parameters. This enables the replacement policy to fetch the pages based on the position for replacement. Scanning through the entire list of allocated pages and updating the position of every page each time is an expensive operation. To avoid such a colossal expense, operating systems will only scan a portion of the list at a given moment of time and updates the corresponding page’s position. The policy that decides on the fraction to scan at a given instance of time is termed as scan rate policy.
Generalities in the model. Habitually on nearing a particular distance to exhaustion, the system starts a kernel level daemon, that runs in concurrence with other processes, termed either as pageout daemon( OpenSolaris and OpenBSD) or Kswapd daemon( Linux); Albeit the name of the process changes based on platform implementation, its intention remains the same .i.e., scan a certain amount of pages, apply the desired replacement policy and evict a set of pages to leeway for the current memory need. The free list of pages might have many waypoints in between the list called watermark. In Common, watermark decides on when to start the scan, rate of scan, number of times to scan, amount of processor utilisation page scanner can take( called CPU CAP), amount of I/O utilisation page scanner can use( called I/O CAP), etc., but the mentioned set varies both in implementation and inclusion based on the platform of implementation. Extensively, many operating systems quantify the measure of watermarks in page numbers.
Implementation In OpenSolaris:
OpenSolaris uses watermark based policy, i.e., scan rate policy changes based on the watermark .
Model. OpenSolaris have three major watermarks, namely lotsfree, desmem, minfree. The system has two different scan policies called slow scan and fast scan. The system also have two different rate at which the scanning will happen per second, i.e., 4times/second and 100times/second. Further, Solaris restricts the CPU utilisation of the page scanner between 4( min_percent_cpu) to 80( max_percent_cpu) percent( Used as a scaling factor) and the I/O is capped at either 40 or 60 IO/second( maxpgio ), but this restriction is based on the formulae 
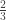
By default lotsfree is 

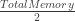
Another watermark worth mentioning is throttlefree. This watermark in general is equated with minfree.

Policy. Once memory reaches lotsfree watermark, pageout daemon kickstarts. The amount of page to scan is determined by the formulae:
![ScanRate= [ [ \frac{lotsfree - freeMem}{lotsfree}] * fastscan + [ \frac{freeMem}{lotsfree} * slowscan] ]](https://s0.wp.com/latex.php?latex=ScanRate%3D+%5B+%5B+%5Cfrac%7Blotsfree+-+freeMem%7D%7Blotsfree%7D%5D+%2A+fastscan+%2B+%5B+%5Cfrac%7BfreeMem%7D%7Blotsfree%7D+%2A+slowscan%5D+%5D&bg=ffffff&fg=333333&s=0&c=20201002)
where freeMem mentions the current instance of free memory in quantity of pages. Intuitively intial values of scan rate is majorly contributed by slow scan, but as it nears the exhaustion fastscan’s value starts increasing and contributing towards scanrate.
CPU utilisation is interpolated with the scanrate by sporadic check and comparison of the time taken to scan n pages ( called PAGES_POLL_MASK hard coded with 1023)with the utilisation.
- CPU utilisation is calculated as follows:
- min_pageout_ticks =
- max_pageout_tick =
- ScalingFactor = max_pageout_tick – min_pageout_tick
- pageout_ticks = min_pageout_tick +
.


- Basically the fraction of memory available with respect to lotsfree is scaled to the ScalingFactor of CPU.
- Between lotsfree and desfree the memory is scanned 4 times/second. Once the memory reaches less than desfree its scanned 100 times/second.
- The throttleFree watermark suspends the allocation of pages that has the wait flag set till scanner brings the memory back above minsfree.
P.S. The same logic is implemented in 4.3BSD, but lotsfree is 
Implementation in FreeBSD:
FreeBSD have a much simple scan policy compared to Solaris and 4.3BSD. The watermarks are replaced by a minimum percent of memory that needs to be maintained. If the memory reaches below this threshold then pageout daemon is started.
Model. FreeBSD divides the pages into 5 categories of pools, namely wired, active, inactive, cache and free. Pages that are unmovable from the physical memory are named wired, pages that is currently part of active execution is called active, pages that are not part of active execution is called inactive, pages that are not used anymore are cached and pages that are not allocated is in free list.
Policy. The system has 2 thresholds, namely minimum and target thresholds. The systems goal is to maintain a minimum threshold of pages in active, cache and freelist, Once the pages reach below the minimum threshold then the pageout daemon kickstarts and starts pushing the pages back to target threshold. By default the values are:
- Free + Cache( free_target) : 3.7% and 9%
- inactive( Inactive_target): 0% and 4.5%
But these values are modifiable through user level interfaces.
Procedure:
- Pageout daemon calculates the minimum required pages that are needed to get above the threshold.
- Tries to acquire the required pages through 3 passes.
- page_shortage = free_target – (free_count + cache_count). Tries to acquire this target. If the achieved target does not satisfy the needed target, then we move to pass 2.
- page_shortage = ( free_target + inactive_target) – ( free_count + cache_count + inactive_count). Tries to acquire this target. If the achieved target does not satisfy the needed, then we move to pass 3.
- kickstart swap out daemon, still all memory is full, then kill the biggest memory consumed process.
- After the 1st pass check the time difference between previous pass and current pass. If the difference is more than lowmem_period(10), then trigger vm_lowmem event. This event tries to decrease many other registered cache sizes and reclaims the same.
Implementation in Linux:
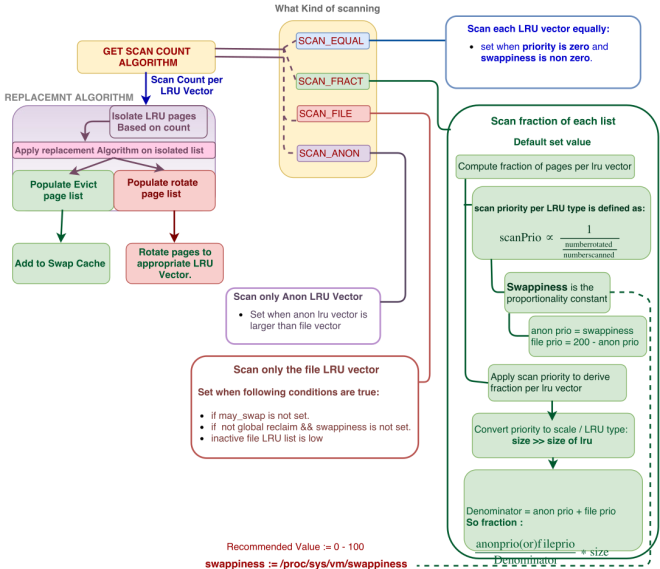
Linux uses watermark amalgamated with demand based scanning, i.e., on allocating a page, the watermark is tested and if the current watermark before the allocation is less than the desired, then try reclaiming the zone directly and also start kswapd if required. The scan amount is based on user defined parameter called swappiness . The reclamation policy is
Model. The Memory( A node in NUMA based machines) is basically divided into zones. Each zone has High, Low and Min watermark. The ratio of the watermarks can be set by the user. Scan rate is determined by variable called swappiness, default value is 60, but can also be set by user, maximum value recommended is 100.

Policy.
- Before allocation, test for Min watermark is made by adding the allocation order count of the request to free page count. If pages are below the low watermark and GFP is not either set to GFP_MEMALLOC, then direct reclamation of the zone is tried with the count of SWAP_CLUSTER_MAX, provided GFP_DIRECT_RECLAIM is set for the allocation request.
- If the GFP is set with GFP_KSWAPD_RECLAIM, then kswapd is triggered to reclaim MAX( SWAP_CLUSTER_MAX, high watermark).
- If the watermark falls below Min watermark then synchronous direct reclamation is attempted, i.e., any allocation request for pages with GFP_WAIT set is suspended on the wait queue. Concurrently kswapd tries to bring back the pages above high watermark.
- In both the cases reclaim uses the following mechanism to scan the pages.
- The variable named priority scan_control decides on the portion of the zone to scan.
- Scan_portion = lru_type_within_zone>> priority.
- Anonyomous page priority(ap) = swappiness.
- File page priority(fp) = 200 – ap.
- Pressure is applied on each zone on file or anon lru formulae derived as:
.
.
- respective pressure is either anonyomous or file page priority.
- Fraction per list Computation
- Denominator = ap + fp .
- Numerator = ap (or) fp.
- Fraction to scan =
.
- Scaling: Fraction to scan is scaled to scan_portion
- Scan_amount = Fraction to scan * Scan_portion.
- Basically, scan portion is scaled to the fraction we derived.
- If the priority is zero and swappiness are non-zero, then Scan count is set to SCAN_EQUAL. This means the ignore the fraction calculation and directly derive the scan count based on the priority for each inactive list.
- The variable named priority scan_control decides on the portion of the zone to scan.
P.S. The statistical variables rotated and scanned is decomposed to half once it reaches a threshold.
intuitively, it is a heuristical thought that reasons with a belief that more the pages are rotated( see Second Chance Algorithm) in a particular lru list then the possibility to reclaim pages from the same are less. Finally, it’s worth to note that described policies are simplified to provide clarity on the core idea.

One thought on “Empathising mammoth’s mentality: A study on Linux Memory Management.”